 Overall scheme for modelling the shape variations associated with liver fibrosis stage and predicting it fromMR images by using PLSR-based shape features (scores)
Overall scheme for modelling the shape variations associated with liver fibrosis stage and predicting it fromMR images by using PLSR-based shape features (scores)
Abstract
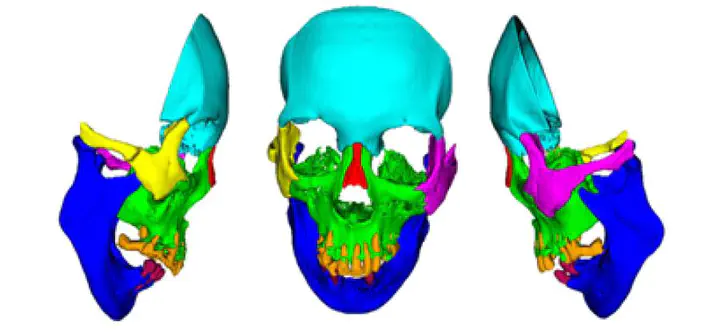
The use of deep learning (DL) in medical imaging is becoming increasingly widespread. Although DL has been used previously for the segmentation of facial bones in computed tomography (CT) images, there are few reports of segmentation involving multiple areas. In this study, a U-Net was used to investigate the automatic segmentation of facial bones into eight areas, with the aim of facilitating virtual surgical planning (VSP) and computer-aided design and manufacturing (CAD/CAM) in maxillofacial surgery. CT data from 50 patients were prepared and used for training, and five-fold cross-validation was performed. The output results generated by the DL model were validated by Dice coefficient and average symmetric surface distance (ASSD). The automatic segmentation was successful in all cases, with a mean± standard deviation Dice coefficient of 0.897 ± 0.077 and ASSD of 1.168 ± 1.962 mm. The accuracy was very high for the mandible (Dice coefficient 0.984, ASSD 0.324 mm) and zygomatic bones (Dice coefficient 0.931, ASSD 0.487 mm), and these could be introduced for VSP and CAD/CAM without any modification. The results for other areas, particularly the teeth, were slightly inferior, with possible reasons being the effects of defects, bonded maxillary and mandibular teeth, and metal artefacts. A limitation of this study is that the data were from a single institution. Hence further research is required to improve the accuracy for some facial areas and to validate the results in larger and more diverse populations.
Mazen Soufi
Assistant Professor
I’m an assistant professor in the Division of Information Science at NAIST, and I apply data-driven approaches to model disease progression from large-scale databases of medical images.