Biography
Mazen Soufi is an assistant professor of information science at Imaging-based Computational Biomedicine lab in Nara Institute of Science and Technology (NAIST). My research focuses on the analysis of disease progression trends based on features dervied from multi-modality medical images (such as MRI, CT or histopathology images). In my work, I use deep learning-based image segmentation algorithms to extract the target organs/structures and perform downstream analysis.
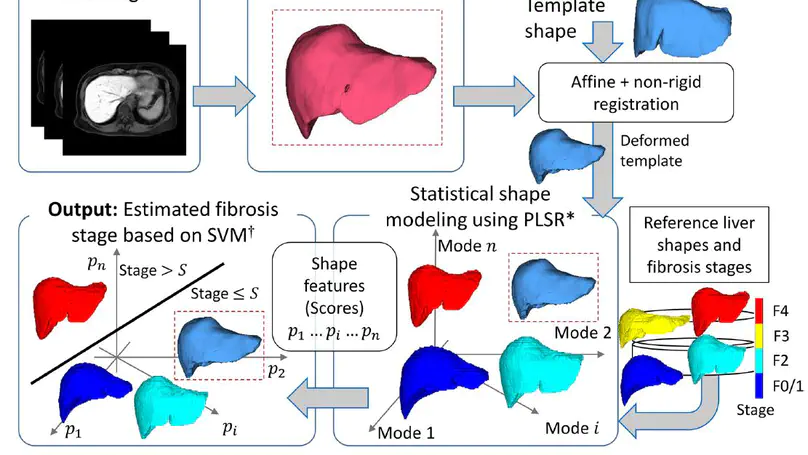
I worked before in projects involving range image-based approaches for monitoring head and neck cancer patients during raditation therapy, prognostic prediction of lung cancer patients using CT image features, and liver fibrosis grading in MR images based on statistical shape analysis. I’m currently interested in the analysis of musculoskeletal (MSK) structures to have insights into the age- and disease-related variations. To pursue this goal, I collaborate with multiple healthcare/medical institutions in Japan and abroad to analyze large-scale (x10,000s volumetric images) databases. I finally aim at developing novel image biomarkers to be used in improving our understanding of aging and disease of the MSK system.
I primiarly use python and the mainstream deep learning frameworks (Tensorflow, PyTorch, MONAI) with the main medical image analysis and visualization libraries (VTK, ITK, Elastix) in my reseach.
Besides my research, I serve as a reviewer for multiple journals and conferences (domestic and international), including MICCAI, Heliyon (Cell), Journal of Applied Clinical Medical Physics, ITE Transactions on Media Technology and Applications, and Advanced Biomedical Engineering.
- Medical Imaging
- Artificial Intelligence & Deep Learning
- Disease Progression & Large-Scale Data Analysis
-
PhD (Health Sciences), 2017
Kyushu University, Japan
-
Master's Degree (Health Sciences), 2014
Kyushu University, Japan
-
BSc (Biomedical Engineering), 2011
Damascus University, Syria
Experience
Responsibilities include:
- Master/PhD course student research mentorship
- Research and development: multiple projects involving MRI, CT and histopathology image analysis
- Teaching
- Lab environment administration (GPU cluster “slurm+singularity” and data servers “Windows Server, NAS”, Fujifilm Vincent workstaion)
- Operation of standing MRI scanner (E-MRI Brio G-Scan, Esaote) for image acquisition
Featured Publications
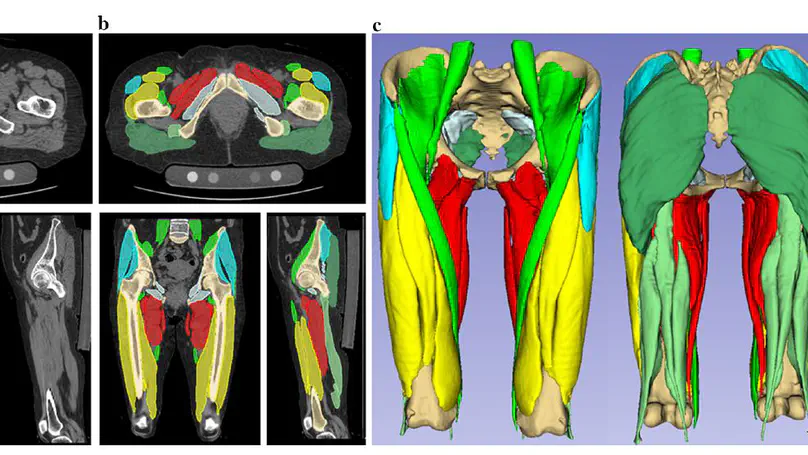
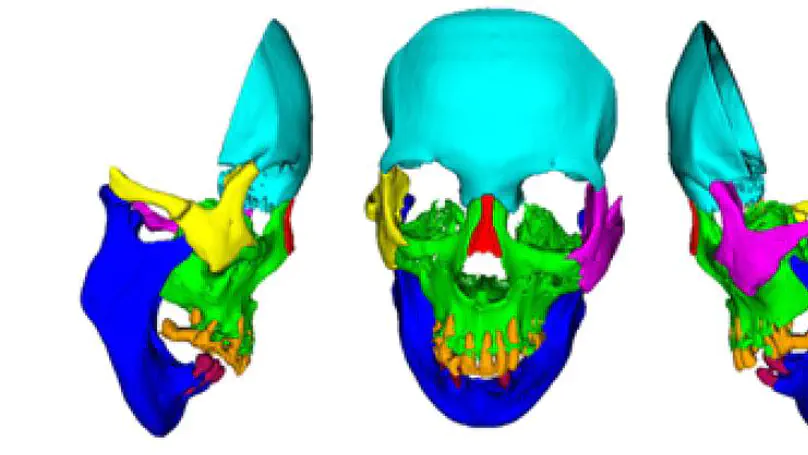
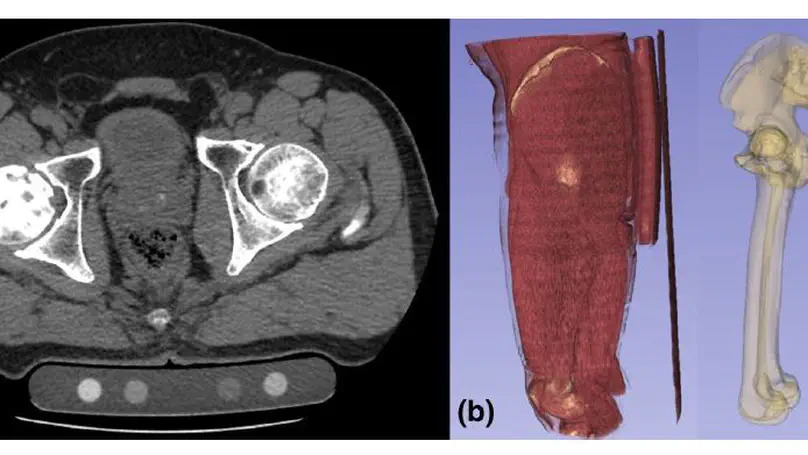
Purpose In quantitative computed tomography (CT), manual selection of the intensity calibration phantom’s region of interest is necessary for calculating density (mg/cm3) from the radiodensity values (Hounsfield units HU). However, as this manual process requires effort and time, the purposes of this study were to develop a system that applies a convolutional neural network (CNN) to automatically segment intensity calibration phantom regions in CT images and to test the system in a large cohort to evaluate its robustness. Methods This cross-sectional, retrospective study included 1040 cases (520 each from two institutions) in which an intensity calibration phantom (B-MAS200, Kyoto Kagaku, Kyoto, Japan) was used. A training dataset was created by manually segmenting the phantom regions for 40 cases (20 cases for each institution). The CNN model’s segmentation accuracy was assessed with the Dice coefficient, and the average symmetric surface distance was assessed through fourfold cross-validation. Further, absolute difference of HU was compared between manually and automatically segmented regions. The system was tested on the remaining 1000 cases. For each institution, linear regression was applied to calculate the correlation coefficients between HU and phantom density. Results The source code and the model used for phantom segmentation can be accessed at https://github.com/keisuke-uemura/CT-Intensity-Calibration-Phantom-Segmentation. The median Dice coefficient was 0.977, and the median average symmetric surface distance was 0.116 mm. The median absolute difference of the segmented regions between manual and automated segmentation was 0.114 HU. For the test cases, the median correlation coefficients were 0.9998 and 0.999 for the two institutions, with a minimum value of 0.9863. Conclusion The proposed CNN model successfully segmented the calibration phantom regions in CT images with excellent accuracy.
Recent Publications
Contact
- msoufi [at] is.naist.jp
- 8916-5 Takayama-cho, Ikoma, 630-0192
- Information Science Bld B, F5, B502